Alejandro Begara Criado

UT Austin Research (NSF)
Reinforcement Learning for Sim-to-Real Quadruped Locomotion
UT Austin REU - Quadruped Locomotion
During the summer of 2025, I worked in the Autonomous Systems Group at the University of Texas at Austin to perform research with quadrupeds.
More specifically, I worked with my research group to develop a reinforcement learning (RL) pipeline to achieve forward locomotion on the Unitree Go2 quadruped using proximal policy optimization (PPO) in the MuJoCo simulator.
The purpose of the research is to develop adaptable and dynamic locomotion behaviors for quadrupeds and establish the foundation for sim-to-real transfer. Furthermore, the research connects to ongoing efforts in Multi-Fidelity Policy Gradient (MFPG) algorithms, which combine low-fidelity simulations, high-fidelity simulations, and limited real-world data to improve training efficiency and transferability.
Through iterative reward shaping via velocity tracking, pose similarity, stability penalties, and the application of domain randomization, the agent learned a relatively stable walking gait in MuJoCo, achieving an average forward velocity of ~0.48 m/s and sustained upright episodes exceeding 83 seconds.
Near the end of the internship, we attempted direct sim-to-real transfer via low-level ROS2 control. Initial trials produced limited forward movement but failed to achieve stable walking. Given the 2.5-month timeframe, a full sim-to-real demonstration was initiated but not completed.
These results highlight both the promise and the limitations of direct sim-to-real transfer
using standard policy gradient methods. Future directions for this work include: (1) establishing a direct sim-to-real baseline from the non-domain randomized policy trained in MuJoCo, (2) transferring the domain-randomized policy trained in MuJoCo to the Go2 to compare robustness, and (iii) integrating policies into a
higher-fidelity simulator such as Isaac Lab to apply multi-fidelity training techniques and close the sim-to-real gap.
For detailed information on the research project and outcomes, please see the report at the end of this page.
My Role and Outcomes
-
Developed an RL pipeline in the MuJoCo simulator with reward shaping to train PPO locomotion policies.
-
Trained non-domain-randomized and domain-randomized policies for sim-to-real baseline tests, achieving a stable forward walking gait with episode lengths exceeding 83 seconds.
-
Conducted policy evaluation and gait analysis using training metrics and simulation videos to improve and select best-performing gaits.
-
Deployed baseline sim-to-real policy transfer tests on the Unitree Go2, achieving initial low-level control.
-
Produced a technical report and open-source repository with documentation, videos, logs, and code.
-
Presented research outcomes at UT Austin’s summer poster session.
Visuals

Figure 1: Unitree Go2 Quadruped (left) and Clearpath Jackal Mobile Robot (right).

Figure 2: Unitree Go2 Joints.
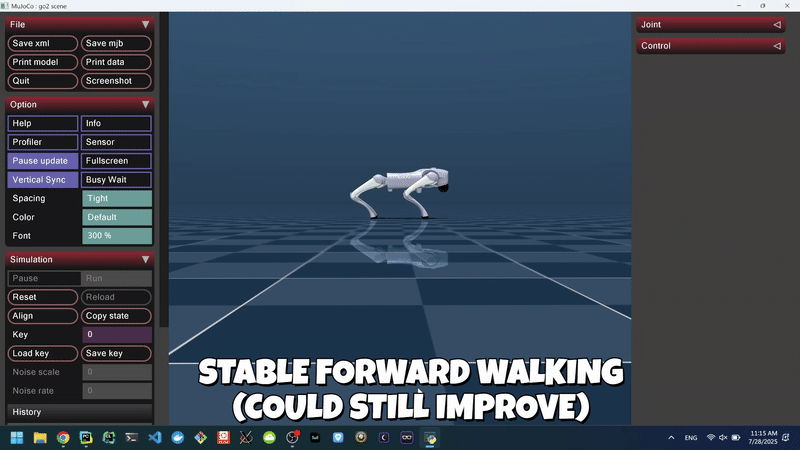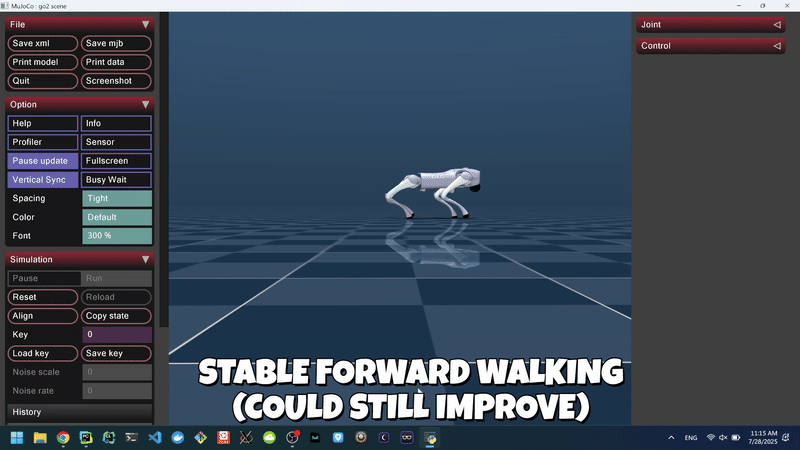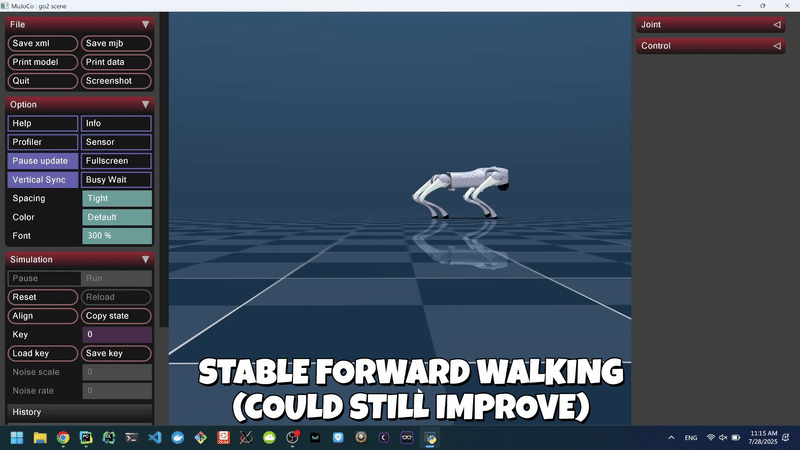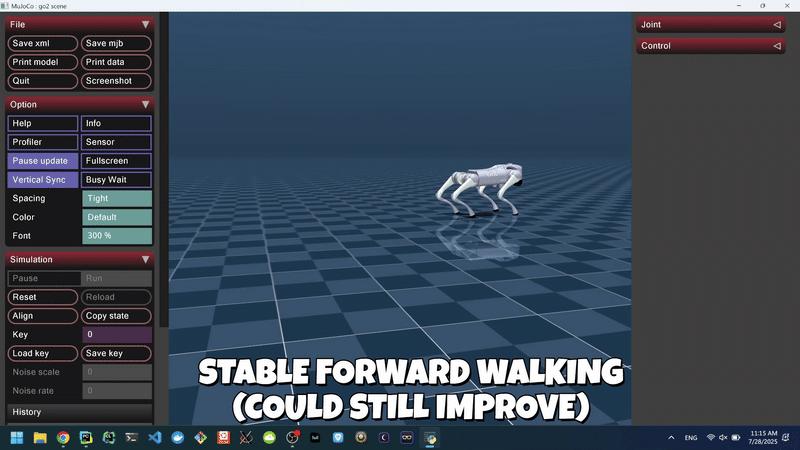
Figure 3: Agent Learned Forward Walking in the MuJoCo Simulator (Non-Domain-Randomized).
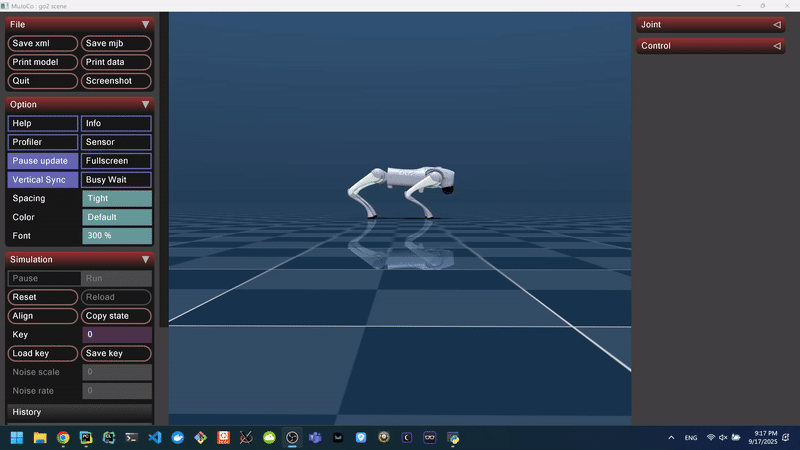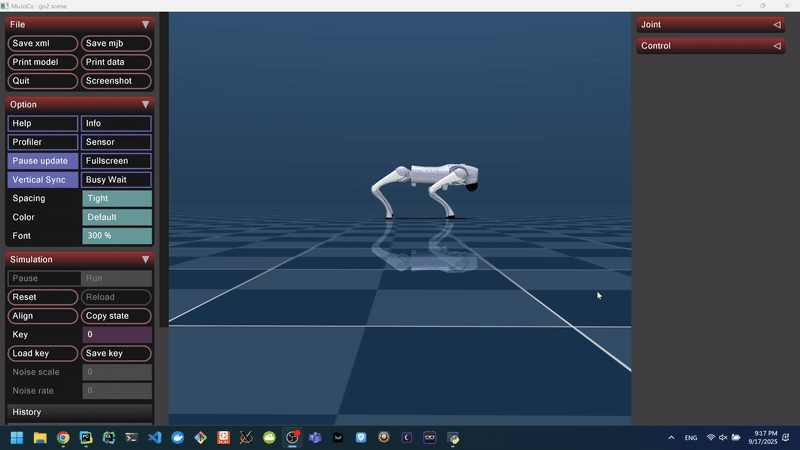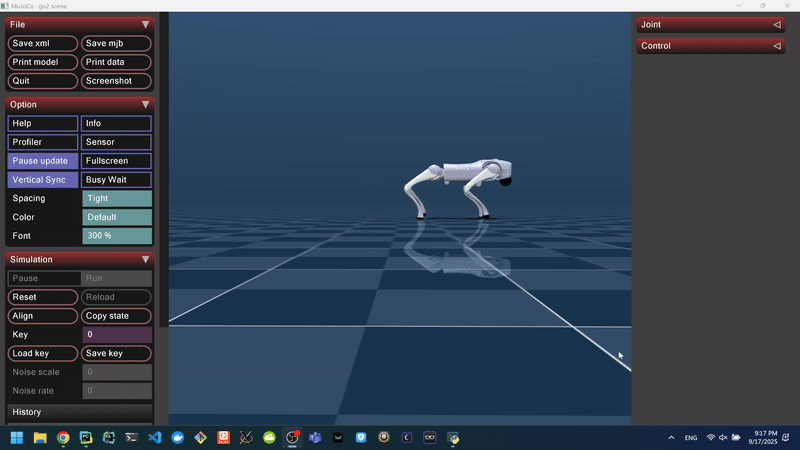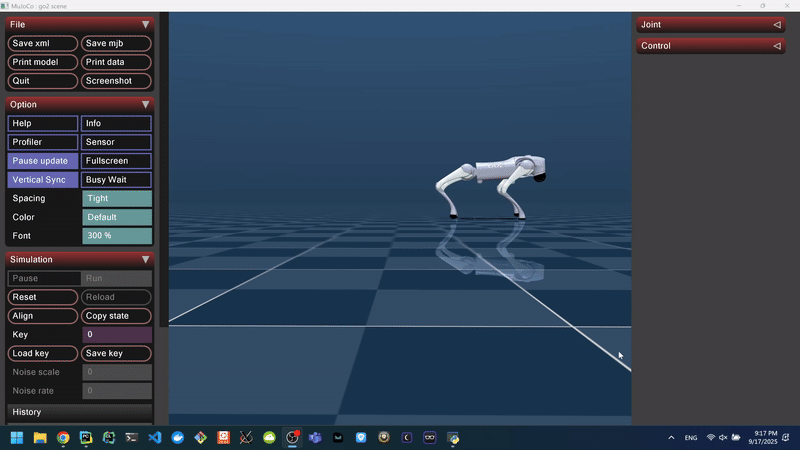
Figure 4: Domain-Randomized Forward Walking Behavior in MuJoCo.

Figure 5: Forward Walking Gait Progression in MuJoCo Simulator (Month 1 - Month 3).

Figure 6: Initial Sim-to-Real Test (Limited Movement).
Additional Visuals

Figure 7: Unitree Go2 and Boston Dynamics Spot (UT Austin Anna Hiss Gym lab).

Figure 8: Unitree Go2 Walking on Ice (Onboard Controller).

Figure 9: Unitree Go2 Obstacle Course Completion.

Figure 10: Drifting Research at UT Austin.
Acknowledgements
Thank you to our mentors Dr. Christian Ellis, Dr. Adam Thorpe, Dr. Neel Bhatt, and Dr.
Ufuk Topcu for their guidance. Thank you to Greta Brown, who worked with me this summer. Thank you to the Autonomous Systems Group at the University of Texas at Austin. Supported by the National Science Foundation (NSF) and the Army Educational Outreach Program (AEOP).